日本語でプロンプトが入力可能になりました

Text to Imageを試す
これまでのLLMとComfyUIの連携は元画像からLLMでプロンプトを生成して新たな画像を作るImage to Imageでした。今回は元になるテキストからLLMでプロンプトを生成して新たな画像を作るText to Imageを試してみることにしました。
LLMのインストール
テキスト系のLLMはgemma2 9Bのみだったので,llama 3.2 3Bとqwen2.5-coder 7Bを新たにインストールしました。
ワークフローの変更
Image to Imageのワークフローの元画像を読み込むノードとOllalma VisionノードをOllama Generateノードに入れ替えるだけでした。
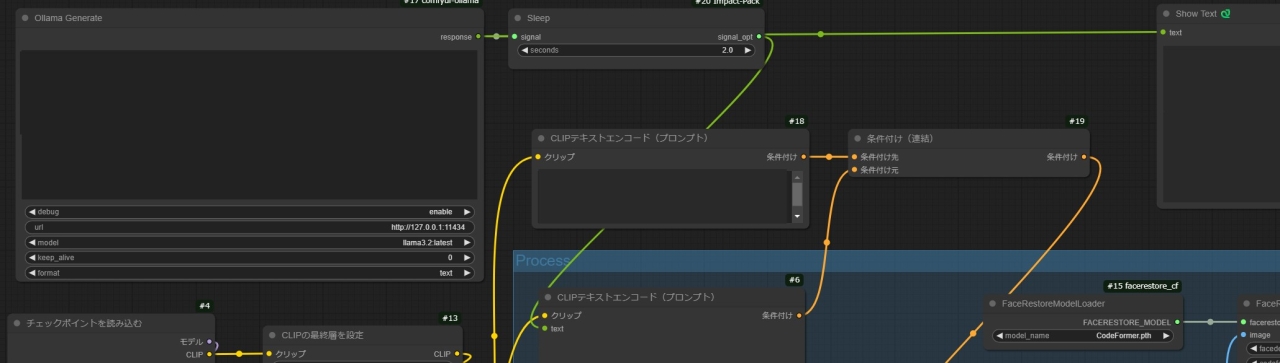
画像生成テスト
英語ができない私としては元になるテキストが日本語でOKというのが大きいです。LLMがいい感じに英語で自然言語のプロンプト(タグのこともありますが…)に変換してくれます。
このプロンプトに,i2iのときと同様に品質系と最低限のプロンプトは追加して画像を生成しました。Pony系モデルとFLUX.1でテストした画像が下のサンプルです。

モデル:waiSemireal_v30

モデル:waiSemireal_v30

モデル:flux1-dev-fp8

モデル:flux1DevPonyPVCTest_v10
Pony系モデルは生成するたびに人物の顔や服装が大きく変化しましたが,FLUX.1はモデルやLLMを変更しても変化が少ない感じでした。
Image to Imageのときは毎回プロンプトを生成していましたが,今回は元のテキストを変更しなければ同じプロンプトを使って画像を生成していました。
LLMによるプロンプトの変化は今回あまり感じませんでした。元のテキストを詳細にすれば変化があるのかもしれませんので,今後もチェックしたいと思います。











この記事へのコメント
コメントはまだありません。
コメントを送る