Joycaptionを使って画像からプロンプトを生成するワークフローを作成しました。アイキャッチは紹介しているワークフローで生成しました。

画像からプロンプトを生成するワークフローの修正
前回紹介したワークフローは,LLMで画像から生成したプロンプトとPony系モデルの品質系プロンプトをConditioning(Combine)というノードで1つにしていたのですが,後から調べるとConditioning(Concat)の方が正しい気がして入れ替えました。
こちらのWebサイトを見ると,Conditioning(Concat)は人物の描き分けにも利用できるみたいなのでワークフローを組んで試してみたいです。
Joycaptionを利用する拡張機能がありました
画像からプロンプトを生成する他の方法がないかWebで調べていると,Joycaption Alpha Two for ComfyUIという拡張機能があることがわかりました。こちらのgithubのリポジトリは中国語のページですが,Google翻訳で日本語にしてみるとインストール手順が書かれていることがわかったので,これを見ながら設定を進めることにしました。
Joycaption Alpha Two for ComfyUI本体はStability Matrixのパッケージ画面からインストールしました。
インストール関連依存と訳された部分に書かれていたpip installで始まるコマンドはターミナルから入力して実行しました。custom_nodesフォルダで実行しないとエラーになります。
(1)~(3)のファイルを指定されたフォルダに配置しました。手動で作業する必要があるのは(3)のみのようです。
(1) google/siglip-so400m-patch14-384
すでにインストールされていました。
(2) unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
リンク先のページからFiles and versionsに進み,表示されているファイルをすべてダウンロードして指定されているフォルダを作成してその中に入れました。自動でインストールされるようなので何もしなくてもいいのかもしれません。
(3) Joy-Caption-alpha-two モデル
リンク先のページからcgrkzexw-599808フォルダ内のファイルをすべてダウンロードして指定されているフォルダを作成してその中に入れました。
ComfyUIを再起動して,上記のWebサイト内の画像ファイルを見ながらカスタムノードを追加してワークシートを作成しました。
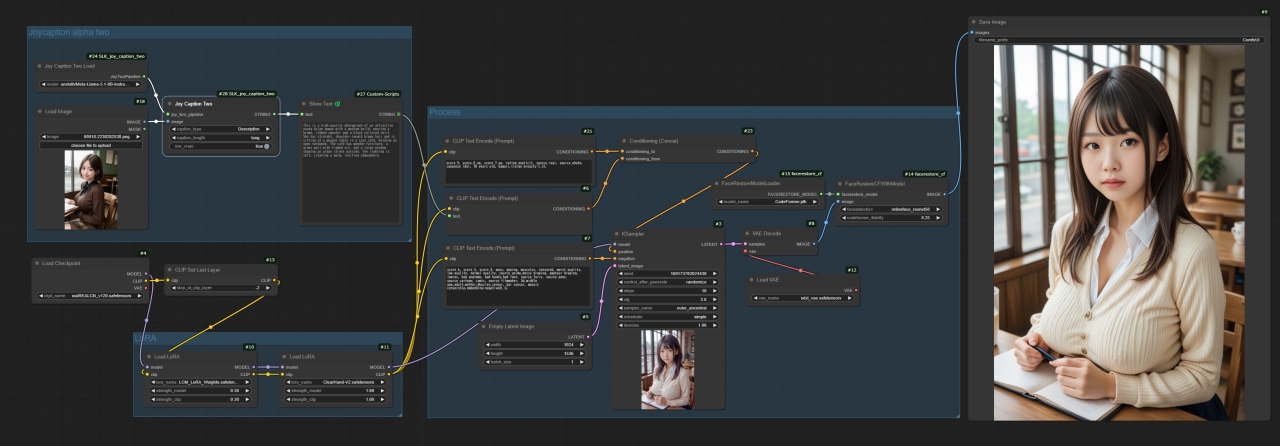
画像生成はうまくいきましたが…
前回作成したワークフローを書き替える形でJoycaptionでプロンプトを生成して画像生成に使うことができました。
目的は達成することができたのですが,最初の1枚を生成するの10分以上の時間がかかることが気になっています。Joycaptionを使って画像からプロンプトを生成する時間,モデルの読み込み時間もあるのですが,特にkSampler以降の処理にものすごく時間がかかるのです。前回のワークフローではこの現象は起こらなかったので,画像から生成されるプロンプトに何らかの違いがあるのではないかと考えています。
Conditioning (Concat)の代わりにString Functionというノードを利用してプロンプトを1つにしたり,Joy Caption Twoノードの設定を変更して試しましたが改善しませんでした。
上記(2)のモデルを削除して自動インストールで入れ直してみましたが,効果ありませんでした。
設定を変更しなければ2枚目以降はプロンプトもそのままで,モデルの読み込みなどもないため1枚12,3秒で生成できるだけに,1枚目を何とかしたいです。
今回のワークフローで生成された画像
Pony系モデルを使っていますが,プロンプトが異なると同じモデルでも生成される画像の印象も変わりますね。出力もおおむね安定している感じがします。




ワークフロー全体はこんな感じです。
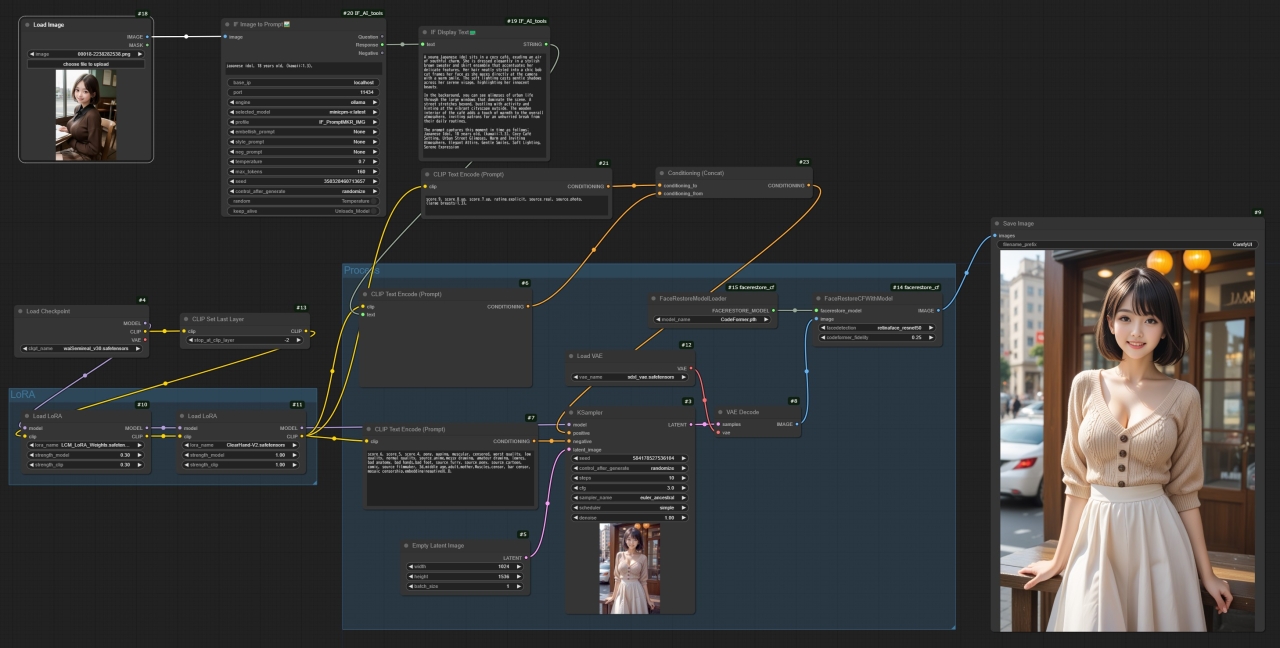
(追記)Empty Lantent ImageとKSsamplerの接続を切った状態で生成を開始するとエラーになり,Joycaptionでプロンプトを生成したところで止まります。ノードを接続して再度生成を開始するとモデルの読み込みから始まり,KSampler以降の処理も速くなることがわかりました。このやり方だと最初の1枚が3分(120秒+55秒)程度で生成できました。アナログなやり方ですが,今のところはこれで良しとしています。
さらに他の方法もあるみたい
Ollama and Llava Vision integration for ComfyUIという拡張機能が使えそうです。こちらはおいおい試してみようと考えています。











この記事へのコメント
コメントはまだありません。
コメントを送る